When one thinks about availability management, the first thing that comes to mind is a percentage with a varying amount of nines after the decimal point. Ah, you say, so the more numbers you have after the decimal, the more accurate the reporting… absolutely not. If you make that assumption, you are surely doomed to fail. The more nines you have, the smaller your allowed downtime or maintenance window in your reporting period.
For the purposes of this article, I will only be discussing infrastructure or component availability. I know we all want to deliver true end-to-end availability management, but getting there is a long, arduous journey with the assumptions that you already have a mature configuration management process in place. This will also assume that you have an application or business service repository, as well as an application performance management solution deployed and operational, says Alan Foley, director at MentPro.
Providing only infrastructure availability is perhaps not ideal, but is certainly a starting point if you are still maturing your availability management process. If you have good configuration management processes in place and perhaps store some information on what applications run on each configuration item, then you can effectively “derive” application availability based on the underlying infrastructure. How, you say? Let me explain.
Identify potential availability data sources
So, what data do I need and how will I use it? If you look at your organisation, you will actually be surprised at the wealth of useful data that is at your disposal. The key is bringing it all together. Here’s a quick list of some potential data sources:
| Availability source | Required metric |
| Configuration management database (CMDB) | * Production configuration items in scope * Are the configuration items nodes or clusters * Are they physical or virtual |
| Service level agreements (SLA) | * Service hours: effectively business hours and non-business hours * Availability targets per configuration item classification: perhaps different physical versus virtual targets or compute classification * Agreed maintenance windows * Business calendar for the year |
| Service desk | * Infrastructure outage availability specific incidents * Changes logged for scheduled downtime |
| Monitoring solution | * Uptime metrics from monitoring agents * Poller uptime metrics |
| Business information | * Organisational structure * Billing information * Stakeholder requirements |
Data analysis: produce true outages
Great, we’ve got the data sources identified, what now? The first point of call is to implement an availability management information system (AMIS) to store all these collected metrics as well as the output from the availability calculations that will be performed during the data analysis process.
Start by collecting all the system uptime data from your monitoring solution. Hopefully, you have these metrics being collected by your monitoring solution and written away to some kind of easily accessible data warehouse; from this data, identify and create your outage records per configuration item. Next, slice and dice the data to ensure that outages are properly classified into the correct service hour windows as per your SLAs. This is extremely important as there may be different availability targets per service window. This is normally the case.
Follow a similar process when analysing your logged maintenance slots as the plan is to overlay your maintenance slots per configuration item onto your outages to effectively cancel valid outages so you are then only left with outages that are outside agreed and signed off maintenance slots. This is normally managed via the change management process. The added advantage of having logged maintenance slots is that your event correlation system will not log unnecessary incidents during this time.
The last step here is to perform the actual availability percentage calculation: the amount of time that the configuration item should be available over the reporting period. This is the agreed service time (AST). (Let’s assume “service” applies to infrastructure, in our case.) Calculate your downtime based on your outages (DT), subtract the downtime from the agreed service time, and then calculate the actual availability percentage. You will no doubt have to do many of these calculations based on your reporting classification as well as your SLA requirements.
Availability = (AST – DT) / AST x 100%
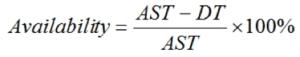
Example availability calculation:
Let’s assume the following for our example:
* The SLA for a particular configuration item for a calendar month (say Aug 2018) is 99.85 % availability.
* The AST for business hours defined for that configuration item is from 8am to 5pm daily.
* AST business hours for the configuration item service window for the month is 198 hours (23 working days – one holiday = 22).
* There is a maintenance slot logged for configuration item for 20 minutes, which falls exactly at the same time as outage two below, but maintenance overran by 30 minutes.
* As per your monitoring agent, there were two outages detected between those business hours for that configuration item:
* Outage one: 20 minutes downtime.
* Outage two: 50 minutes downtime.
Calculation:
= ((198 AST Business Hours*60 Minutes) – (Outage1 {20} + (Outage 2{50} – Outage 2{Maintenance Slot} {20})) / (198 Business Hours*60 Minutes)*100
= 99.58 %
In this example, the configuration item SLA has not been met for August 2018.
If Application B was running on this server and it was a server that was not clustered, you could derive Application B availability based on the underlying infrastructure availability, not ideal, as application availability should really be monitored and reported on using an application performance management tool, but at least you have an auditable measurement.
Reporting and trending
Once you have done all the analysis, you can now point your preferred reporting solution to your AMIS and produce your weekly or monthly reports. Important information to include in your reporting could be the following:
* Availability achieved versus availability target per configuration item or per compute classification.
* Availability measurement per configuration item in scope: effectively, do you have availability data for all configuration items in scope?
* Availability achieved per service hour windows, normally aggregated per compute or other SLA requirement.
* Availability achieved per SLA definition.
It’s important to write away your calculated availability and configuration item counts into trending tables in your AMIS; this is crucial to see if you are improving or worsening over time. Your trending can also show you your configuration items have grown and all this information can now be used in your availability plan. A good start would be to provide trending on a weekly and monthly basis.
Data correlation: adding the business value
Okay, so we’ve got the magic availability percentage we spoke about initially. Great as a start, but business needs a bit more. They may want to see availability by company organisational structure or they may need use availability figures as a factor in their monthly billing, or they may want other unique reporting requirements. This is where correlating infrastructure, business information, service level agreements and billing information adds so much more value than a simple availability percentage. Providing availability reporting in the right context so it can be used effectively is a superb business value add.
Conclusion
While you are working on providing true end-to-end availability, this will at least give you an opportunity to produce some kind of availability reporting that can be used as input to tweak service level agreements you may have with customers. In my experience, the greatest hidden business value add is that you provide invaluable feedback to the configuration management team to seriously mature and improve their configuration item information. The information can now be used as the “single and reliable version” of the truth by all infrastructure and operations departments.